Lambda architecture for distributed mobile sensor
In "Internet of Things" setups large amounts of data are generate from sensors and communication. The large amount of data results in a high complexity which makes the data hard to handle and complex to analyse. Nathan Marz developed the lambda architecture to reduce the rising complexity.
The goal of this project is it to create a lambda architecture, with current technology like Apache Spark to process generated by mobile sensor nodes.
- Batch layer
- Speed layer
- Serving layer
- Dashboard
- Test data generator
| Role/Name | Description |
|---|---|
| Mike Wüstenberg | Documentation, Research, Programing |
Table 1. Stakeholder

Figure 1. Business Context
| Component | Explanation |
|---|---|
| Loomo | Provides sonsore data such as Odometry data |
| Test Data Generator | Generates test data for testing and experiment's |
| Find3 | Provides WiFi signal data such as signal strength |
| Lambda Architecktue | Stores and processes the collected data |
| Grafana Dashboard | Visualisation of the data |
Table 3. Business Context
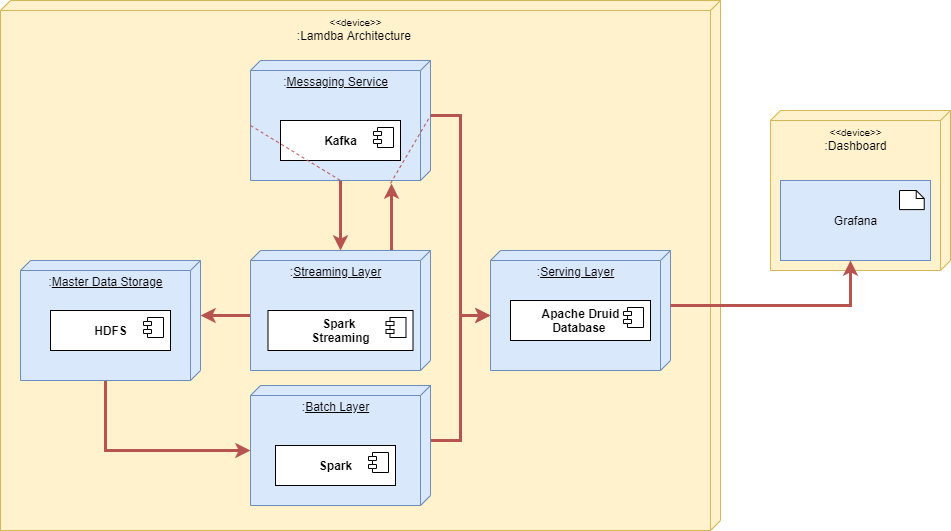
Figure 2. Technical Context
| Component | Input | Output |
|---|---|---|
| Loomo | none | Generates Sensore data |
| Test Device | none | Generates Test data |
| Messaging Service | Raw Sensore data from Loomo, Test Device | Raw Sensore data to Streaming layer |
| Transformed data from Streaming Layer | Transformed data to Serving Layer | |
| Streaming Layer | Raw Sensore Data from Messaging Service | Saves data to HDFS |
| none | Tranformed data to Messaging Service | |
| Master Data Storage | Raw Data from Streaming Layer | Archived data to Batch Layer |
| Batch Layer | Archived Date from Master Data Storage | Transformed data to Serving layer |
| Grafana | Processed data stored in Druid | Dashboard |
Table 4. Technical Context
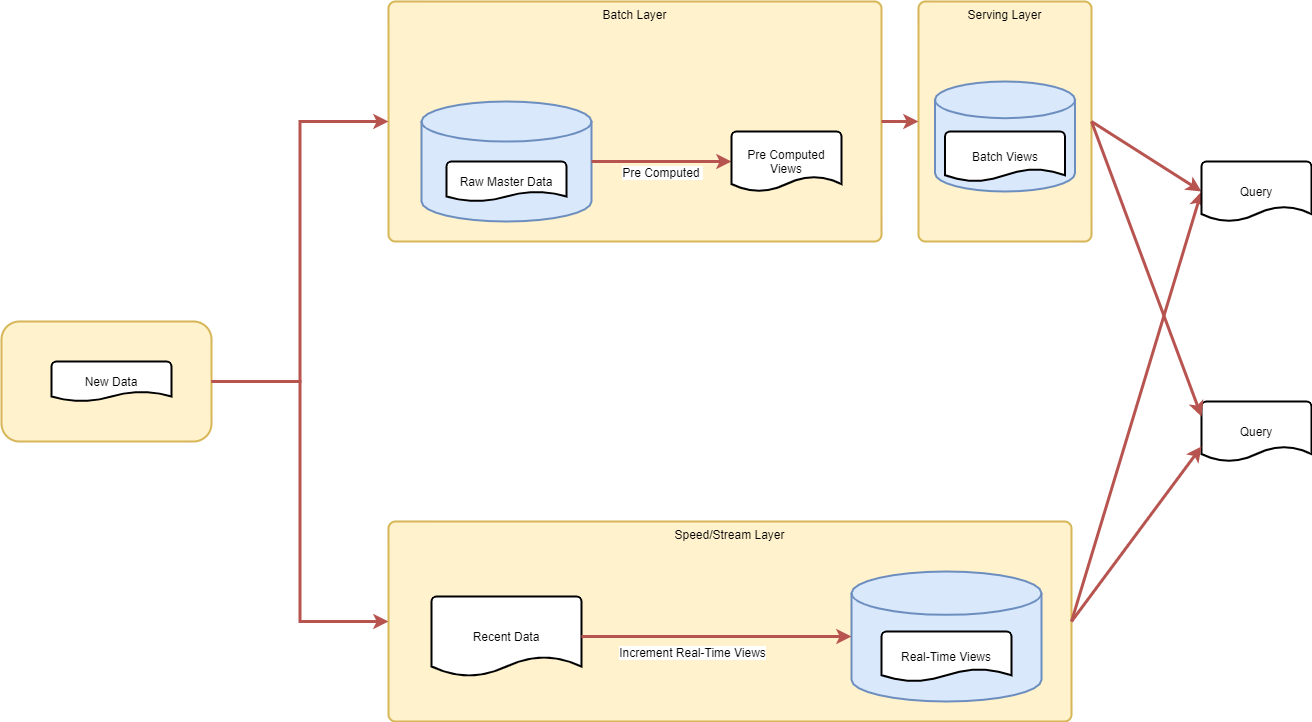
Figure 3-1. Lambda Architecture Clean
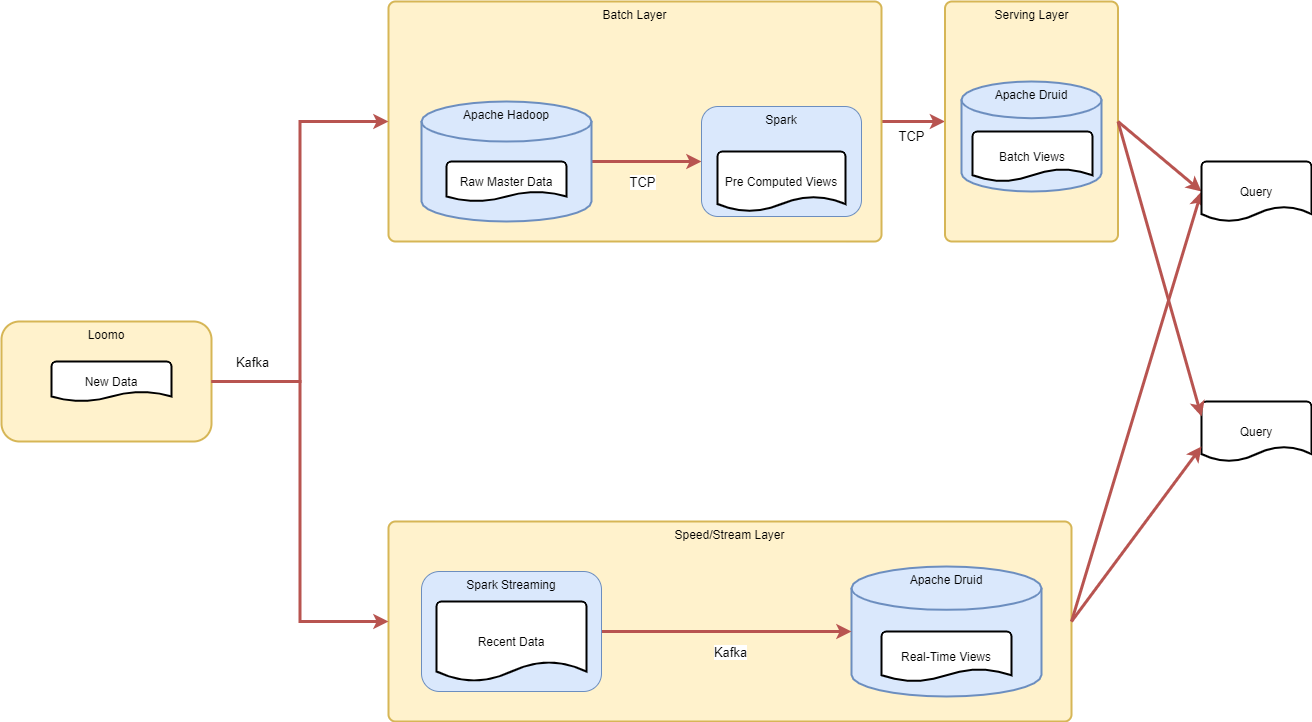
Figure 3-2. Lambda Architecture Technology
Technologies
- Input
- Apache Kafka: Transmission of Data
- Batch Layer
- Hadoop HDFS: Persistent distributed data storage
- Spark
- Speed Layer
- Spark Streaming
- Serving Layer
- Apache Druid
- Visualisation
- Grafana Dashboard
todo: spark-streaming, spark-batch, spark-experiment Folder structure
- src
- dataGenerator
- producer-find3
- spark
- dataGenerator
The project start a variety of different docker container for its services. in the Diagram below(Figure 5-1) you can see the important Ports and communication connection between the containers and the world outside the "lambda-network".
The "host_ip" represents the IP address of your docker host system and changes depending on your host systems IP address.
The "Kafka" container can be configured to listen to more then one IP address at a time and is so by default.
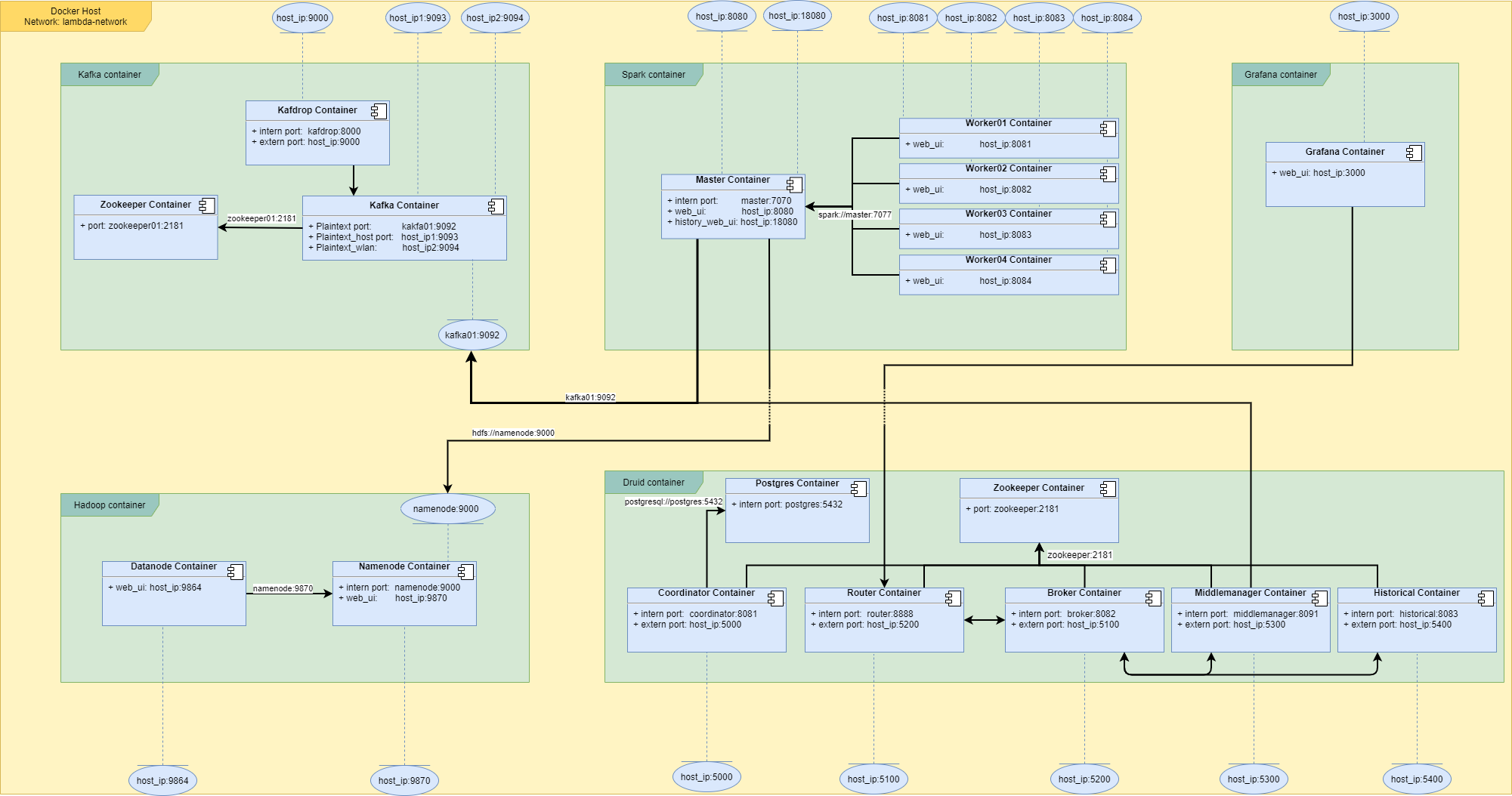
Figure 5-1. Lambda Architecture Technology
This Java programs purpose is to generate consistent test data and send it via Kafka to the Lambda architecture. The test data is generated in random generate batches but each batch will look the same. The size and and number of batches send can be configured inside the program. The data is serialised into a "Avro" format and send to a "Kafka" service.
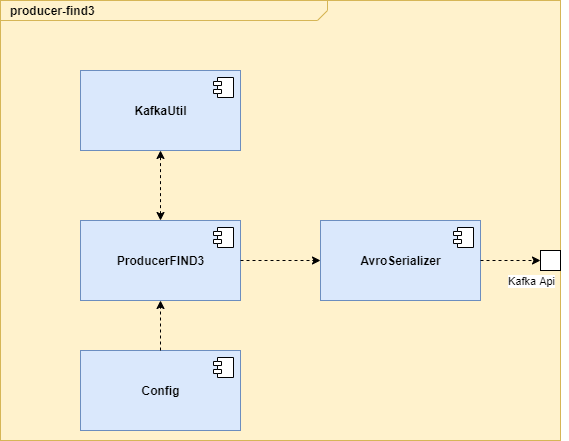
Figure 4-1. Producer-Find3 Blockview
| Component | Purpose |
|---|---|
| ProducerFIND3 | Build batch test data and send them to kafka |
| Config | Configuration of Kafka connection address, batch size and more. |
| KafkaUtil | Utility methods for data generation |
| AvroSerializer | Serializer for Java object into Avro byte stream |
Table 5. Producer-Find3 Blockview
{
"type": "record",
"name": "AvroFIND3Data",
"namespace": "app.model.avro.generated",
"fields": [
{"name": "senderName", "type": "string", "doc": "Name of the sender"},
{"name": "location", "type": "string", "doc": "Location of the device based on wifi data"},
{"name": "findTimestamp", "type": "string", "doc": "Timestamp of data entry"},
{"name": "odomData", "type": { "type":"array", "items": "string"},"default": []},
{"name": "wifiData", "type": {"type": "map", "values": "int"}, "default": {}}
]
}-
senderName: fixed name(Data01)
-
location: fixed location of r287 or r288
-
findTimestamp: current Timestamp in epoch second format
-
odomData: Json string containing 4 entrys of odometry data. Each entry contains x,y,z for position and x,y,z,w for its rotation. The rotation is a fixed double value. The position are randomly generated.
- position between: x(00-10) and y(00-10)
- position between: x(20-30) and y(00-10)
- position between: x(20-30) and y(20-30)
- position between: x(20-30) and y(0-10)
-
wifiData: List of 18 access points with a double value between -30 and -90
About arc42
arc42, the Template for documentation of software and system architecture.
By Dr. Gernot Starke, Dr. Peter Hruschka and contributors.
Template Revision: 7.0 EN (based on asciidoc), January 2017
© We acknowledge that this document uses material from the arc 42 architecture template, http://www.arc42.de. Created by Dr. Peter Hruschka & Dr. Gernot Starke.